

Building my Personal LLM Wiki (Part 2): The Technical Implementation
Following up on my previous post on what prompted me to build my personal LLM Wiki, here is the promised technical flow (per Claude Code). Note that some of the domains are placeholders and you should be able to create as many of your own as you like. And bonus, I built a front end for it with Codex. Here is what it looks like.
What This Is
A personal wiki where an LLM (Claude) acts as librarian — ingesting sources, compiling knowledge, maintaining connections, and tracking freshness. Built on Andrej Karpathy’s pattern, extended with lifecycle management inspired by production memory systems.
Current scale: 39 pages across 5 domains, 68 relationship edges, 52 unique tags, automated health monitoring.
Stack: Claude Code + Obsidian + Python
Architecture
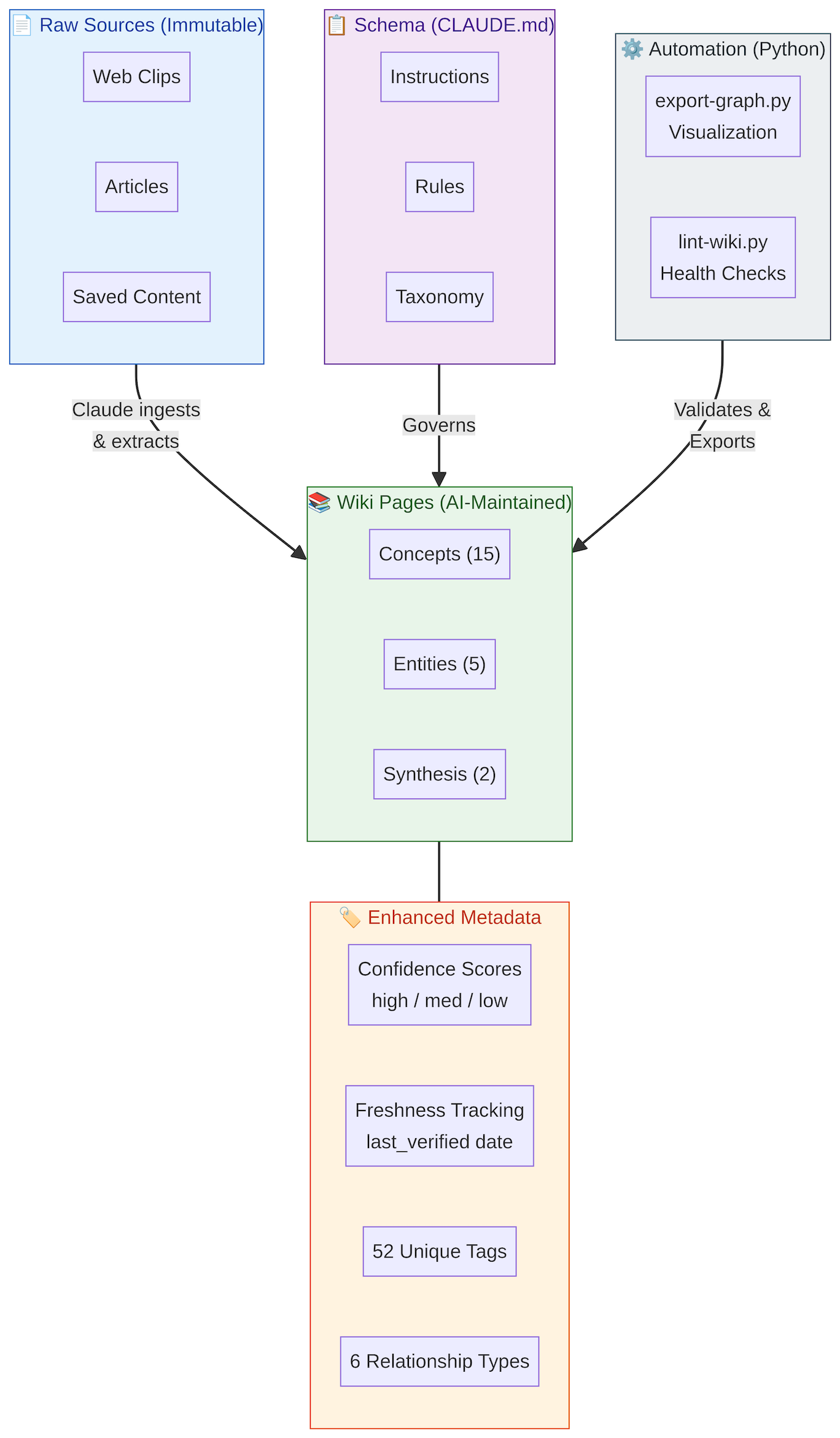
System Architecture — Four-layer stack from raw sources through AI-maintained wiki pages, governed by schema, validated by automation
The system is organized into four layers.
Raw Sources are immutable — web clips, articles, and saved content that serve as the permanent record.
Wiki Pages are AI-maintained and contain the distilled knowledge: concepts, entities, and synthesis documents, each enhanced with confidence scores, freshness tracking, tags, and typed relationships.
The Schema layer (CLAUDE.md) provides the instructions, rules, and taxonomy that govern how Claude processes content.
Finally, the Automation layer uses Python scripts (export-graph.py for visualization, lint-wiki.py for health checks) to validate and export the wiki state.
Lifecycle Management
1. Confidence Scores
Every page is rated based on source count, recency, and contradictions:
confidence: high # Multiple recent sources, verified
confidence: medium # Single/older sources, uncertainties
confidence: low # Speculative, contradictory, needs work
This prevents outdated knowledge from appearing authoritative. In a domain like AI where the landscape shifts monthly, a page written six months ago about model capabilities may be actively misleading without a confidence signal.
2. Freshness Tracking
last_verified: 2026-04-13
Automated alerts fire for pages older than 90 days. Tech knowledge has a shelf life - this mechanism ensures stale pages surface for review rather than silently decaying.
3. Typed Relationships
Beyond simple wiki links, the system maintains semantic connections between pages:
relationships:
implements:[[Abstract Concept]] # Concrete realization
supports:[[Claim]] # Evidence for
contradicts:[[Opposing View]] # Conflicts with
extends:[[Base Concept]] # Builds upon
used_by:[[Dependent]] # Practical applications
supersedes:[[Old Page]] # Replaces
Real example — the Claude Code entity page:
implements:[[Multi-Agent Coordination Patterns]]
supports:[[Vibe Coding]], [[Product Builders]]
used_by:[[AI Harness Design]], [[Claude Skills]]
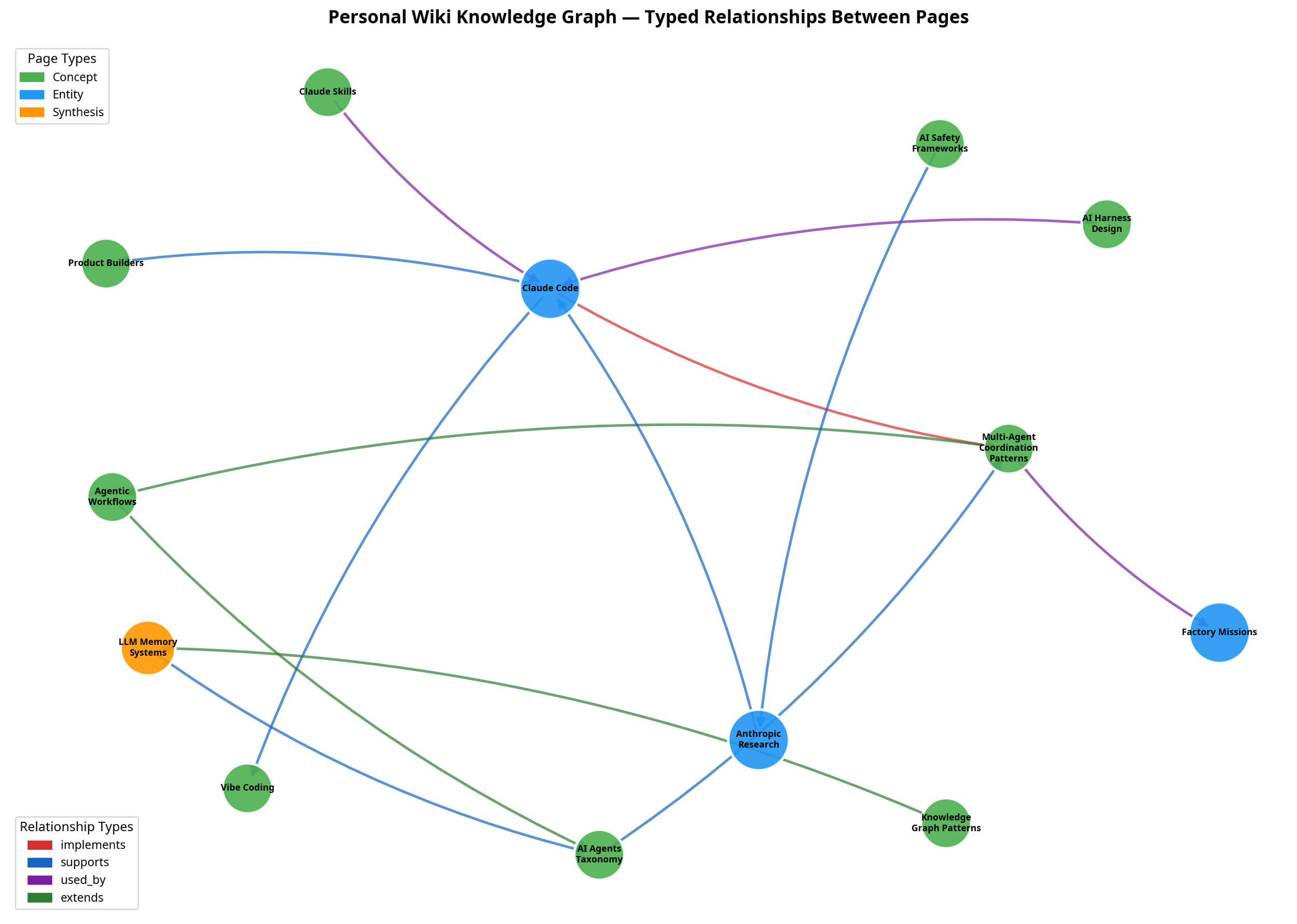
Knowledge Graph — Typed relationships between wiki pages, color-coded by page type (concept, entity, synthesis) and relationship type (implements, supports, used_by, extends)
Why this matters: You can trace chains of reasoning, surface contradictions, and track knowledge evolution. When a new source contradicts an existing page, the contradicts relationship makes the conflict explicit rather than silently overwriting.
4. Tag Taxonomy
Tags enable filtering and clustering across the wiki:
tags:[ai-agents, architecture, anthropic, coordination, patterns]
Examples
Domains ai-agents, ai-safety, product-management, design
Themes automation, coordination, transformation
Companies anthropic, openai
Formats patterns, benchmarks, architectures
Automation Tools
export-graph.py
Generates visualization-ready data from the wiki:
python3 export-graph.py
# Outputs:# - wiki-graph.json (full graph data)
# - wiki-graph-summary.md (stats)
Compatible with Obsidian graph view, D3.js, and Graphviz.
lint-wiki.py
Automated health checks across seven dimensions: ✓ Freshness (90+ days)# ✓ Confidence scores# ✓ Broken relationships# ✓ Contradictions# ✓ Supersession tracking# ⚠ Orphan pages (12)# ✓ Oversized pages (>300 lines)
python3 lint-wiki.py tech
Core Operations
INGEST (Enhanced)
The enhanced ingest flow processes a raw source through eight steps:

Ingestion Flow
User: "Ingest my clips from today"
Claude:
1. Find new clips in Clippings/ folder
2. Read and identify domain
3. Save to domains/[domain]/sources/
4. Extract 5-15 key concepts
5. Create wiki pages with: - Tags from taxonomy - Confidence score - Typed relationships - last_verified = today
6. Update index
7. Log operation
8. Run LINT check
Takes approximately 2-3 minutes per source. Cost: ~$0.10-0.20.
QUERY (Enhanced)
Search by title, tags, or relationship traversal:
User: "What supports the AI adoption claim?"
Claude:
1. Search wiki pages tagged 'ai-adoption'
2. Follow 'supports' relationships
3. Read supporting pages
4. Synthesize with citations
5. Note confidence levels
LINT (Automated)
python3 lint-wiki.py all
# Validates:# - All pages verified recently# - All have confidence scores# - All relationships valid# - No contradictions untracked# - No broken supersession chains
Runs in 1-2 seconds. Zero cost (Python only).
Quick Start
Step 1 — Structure: Create the directory skeleton.
Step 2 — Schema: Create CLAUDE.md defining the page format with lifecycle fields, tag taxonomy for your domains, the 6 relationship types and their semantics, and the INGEST/QUERY/LINT workflows.
Step 3 — Automation: Copy export-graph.py and lint-wiki.py from the repo.
Step 4 — First Ingestion:
cp ~/article.md domains/tech/sources/#
In Claude Code:# "Ingest domains/tech/sources/article.md with full metadata"# Claude creates pages with tags, confidence, relationships
Step 5 — Validate:
python3 lint-wiki.py techpython3 export-graph.py# Open in Obsidian to see graph visualization
Real-World Workflow
Daily capture: Clip 3-5 articles while reading (Obsidian Web Clipper). Evening: “Ingest clips from today.” Result: tagged, scored, related, validated.
Monthly maintenance: Run python3 lint-wiki.py all. Fix P1/P2 issues (stale pages, broken links). Ignore P3 (orphans naturally resolve as more content is added).
Content generation: Research by ingesting 10 sources on a topic. Synthesize: “What patterns emerge?” Write: “Turn this page into a blog post with contradiction acknowledgment.”
Limitations
The system currently has four known constraints: it is single-user with no collaboration support, English-only, text-focused with limited media handling, and relies on manual relationship mapping (AI suggests, human confirms).
Resources
Pattern origins:
Karpathy: https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
Evolution: https://gist.github.com/rohitg00/2067ab416f7bbe447c1977edaaa681e2
Tools:
Claude Code: https://claude.com/claude-code
Obsidian: https://obsidian.md